This was a collaborative effort between multiple squads in the team, which resulted in moving the blog from blog.ubuntu.com to ubuntu.com/blog. This is now live with redirects from the old links to the new home of blog.
Brand squad champion a consistent look and feel across all media from web to social to print and logos.
Marketing support
We completed a few documents for the Marketing team, datasheets and a whitepaper.
Suru exploration
We did some initial exploration work on how we can extend the use of Suru across the webs. We concentrated on use in the header and footer sections of bubble pages. The aim is to get consistent use across all our websites and guideline how it is to be used in order to help the development teams going forward.
Illustrations
We pushed on with the development of our illustrations, completing an audit of illustrations currently used across all our websites and putting a plan in place to update them in stages.
We designed an illustration for ‘The future of mobile connectivity’ to go in a takeover on Ubuntu.com
Iconography
Finalised a list of UI icons with the UX teams with a view to create a new complete set to go across all our products, delivering a consistent user experience.
Slide deck tutorial
We completed the first stage of a video tutorial to go alongside the Master slide deck that guides you on how to use the new deck, do’s and dont’s, and tips for creating great looking slides.
MAAS
The MAAS squad develop the UI for the maas project.
Understand network testing
As the engineers are starting to flesh out their part of the spec for network testing in MAAS – a new feature aimed at the 2.7 release, the UX team spent a significant amount of time learning and understanding what network testing implies and how it will work. We began creating initial sketches to help both the design and the engineering team think in line for what the UI could look like.
Upgrade to Vanilla 2.0
We upgraded the MAAS application to Vanilla 2.0, making use of all the great features introduced with it. As things the new version of the framework introduces quite a few changes, there are a number of issues in the MAAS UI need to be fixed – the work for this was started and will continue in the next iteration.
Implement small graphs for KVM listing
We are introducing new small graphs within a table, that will, to begin with, be used in the KVM and RSD pages, allowing the users to at-a-glance see their used and available resources. The work for this began with implementing graphs and infotips (rich tooltips) displaying storage and will continue in the next iteration with graphs displaying cores.
JAAS
The JAAS squad develops the UI for the JAAS store and Juju GUI projects.
Juju status project
We gathered which pieces of information would be good to display in the new Juju status project. The new GUI will help Juju to scale up, targeting users with lots of Juju/models, stitching all bootstrapping together. Status of all models with metadata about the controllers, analytics and stats. JAAS is the intersection of Juju, CLI, models and solutions.
Jaas.ai enhancements
We have worked on an update to the homepage hero area to include a slideshow. This will help to promote different types of content at the homepage.
Vanilla
The Vanilla squad design and maintain the design system and Vanilla framework library. They ensure a consistent style throughout web assets.
Released Vanilla 2.0
Over the past year, we’ve been working hard to bring you the next release of Vanilla framework: version 2.0, our most stable release to date.
Since our last significant release, v1.8.0 back in July last year, we’ve been working hard to bring you new features, improve the framework and make it the most stable version we’ve released.
You can see the full list of new and updated changes in the framework in the full release notes . Alternatively you can read up on high-level highlights in our recent blog post New release: Vanilla framework 2.0, and to help with your upgrade to 2.0 we’ve written a step-by-step guide to help you along the way.
Site upgrades
With the release of Vanilla 2.0 we’ve been rolling upgrades across some of our marketing sites.
These pages are generating an aggregated traffic around ~2000 visits per day since they launched, they keep growing without having performed any specific campaign.
Release UI drag’n’drop
The Release UI has received some love this iteration. We’ve updated the visual style to improve usability and worked on drag’n’dropping channels and releases – which will be landing soon.
There was some refactoring needed to make the right components draggable, and we took the opportunity to experiment with React hooks. This work was the foundation for a better release experience and flexibility that we’ll be working on in the coming iteration.
Commercial applications
Responsive UI layout
The UI for the base application is now responsive and has been optimised for tablet and mobile devices. The work comprised of two components:
Modifying the existing CSS Grid layout at certain breakpoints, which was relatively simple, and;
Migrating the react-virtualized tables to react-window (a much leaner alternative for virtualized lists) and making them responsive. This piece of work was substantially more difficult.
Candid
Candid is our service which provides macaroon-based authentication.
Multi log-in, implementation of the design
Candid has the ability to login to a selection of registered identity providers. We required an interface to select the provider you want to use to authenticate with. This task included applying Vanilla framework to the existing views with improvements on performance and maintainability.
Mobile operators face a range of challenges today from saturation, competition and regulation – all of which are having a negative impact on revenues. The introduction of 5G offers new customer segments and services to offset this decline. However, unlike the introduction of 4G which was dominated by consumer benefits, 5G is expected to be driven by enterprise use. According to IDC, enterprises will generate 60 percent of the world’s data by 2025.
Rather than rely on costly proprietary hardware and operating models, the use of open source technologies offers the ability to commoditise and democratise the wireless network infrastructure. Major operators such as Vodafone, Telefonica and China Mobile have already adopted such practices.
Shifting to open source technology and taking a software defined approach enables mobile operators to differentiate based on the services they offer, rather than network coverage or subscription costs.
This whitepaper will explain how mobile operators can break the proprietary stranglehold and adopt an open approach including:
The open source initiatives and technologies available today and being adopted by major operators.
How a combination of software defined radio, mobile base stations and 3rd party app development can provide a way for mobile operators to differentiate and drive down CAPEX
Use cases by Vodafone and EE on successful implementations by adopting an open source approach
To view the whitepaper, sign up using the form below:
<noscript><a class="p-link--external" href="https://ubuntu.com/engage/ubuntu-lime-telco?utm_source=Blog&utm_medium=Blog&utm_campaign=FY19_IOT_UbuntuCore_Whitepaper_LimeSDR">Get the whitepaper</a>
</noscript>
I have many problems with YouTube, who doesn’t these days, right? I’m not going to go into all the nitty gritty of it in this post, but here’s a video from a LBRY advocate that does a good job of summarizing some of the issues by using clips from YouTube creators:
I have a channel on YouTube for which I have lots of plans for. I started making videos last year and created 59 episodes for Debian Package of the Day. I’m proud that I got so far because I tend to lose interest in things after I figure out how it works or how to do it. I suppose some people have assumed that my video channel is dead because I haven’t uploaded recently, but I’ve just been really busy and in recent weeks, also a bit tired as a result. Things should pick up again soon.
Mediadrop and PeerTube
I wanted to avoid a reliance on YouTube early on, and set up a mediadrop instance on highvoltage.tv. Mediadrop ticks quite a few boxes but there’s a lot that’s missing. On top of that, it doesn’t seem to be actively developed anymore so it will probably never get the features that I want.
Screenshot of my MediaDrop instance.
I’ve been planning to move over to PeerTube for a while and hope to complete that soon. PeerTube is a free software video hosting platform that resemble YouTube style video sites. It’s on the fediverse and videos viewed by users are shared by webtorrents to other users who are viewing the same videos. After reviewing different video hosting platforms last year during DebCamp, I also came to the conclusion that PeerTube is the right platform to host DebConf and related Debian videos on. I intend to implement an instance for Debian shortly after I finish up my own migration.
Above is an introduction of PeerTube by its creators (which runs on PeerTube so if you’ve never tried it out before, there’s your chance!)
LBRY
LBRY App Screenshot
LBRY takes a drastically different approach to the video sharing problem. It’s not yet as polished as PeerTube in terms of user experience and it’s a lot newer too, but it’s interesting in its own right. It’s also free software and implements it’s own protocol that you access on lbry:// URIs and it prioritizes it’s own native apps over accessing it in a web browser. Videos are also shared on its peer-to-peer network. One big thing that it implements is its own blockchain along with its own LBC currency (don’t roll your eyes just yet it’s not some gimmick from 2016 ;) ). It’s integrated with the app so viewers can easily give a tip to a creator. I think that’s better than YouTube’s ad approach because people can earn money by the value their video provides to the user, not by the amount of eyes they bring to the platform. It’s also possible for creators to create paid for content, although I haven’t seen that on the platform yet.
If you try out LBRY using my referral code I can get a whole 20 LBC (1 LBC is nearly USD $0.04 so I’ll be rich soon!). They also have a sync system that can sync all your existing YouTube videos over to LBRY. I requested this yesterday and it’s scheduled so at some point my YouTube videos will show up on my @highvoltage channel on LBRY. Their roadmap also includes some interesting reading.
I definitely intend to try out LBRY’s features and it’s unique approach, although for now my plan is to use my upcoming PeerTube instance as my main platform. It’s the most stable and viable long-term option at this point and covers all the important features that I care about.
The purpose of this communication is to provide a status update and highlights for any interesting subjects from the Ubuntu Server Team. If you would like to reach the server team, you can find us at the #ubuntu-server channel on Freenode. Alternatively, you can sign up and use the Ubuntu Server Team mailing list or visit the Ubuntu Server discourse hub for more discussion.
Spotlight: Weekly Ubuntu Server team updates in Discourse
The Ubuntu Server team will now be sending weekly team updates to discourse to give a clear view of the projects, feature and bug work we are working on each week. Come see what we are up to and participate in driving Ubuntu Server changes with us. Here is our June 24 status update. Come discuss any topics of interest with us.
cloud-init
doc: indicate that netplan is default in Ubuntu now [Daniel Watkins]
azure: add region and AZ properties from imds compute location metadata [Chad Smith]
sysconfig: support more bonding options [Penghui Liao]
cloud-init-generator: use libexec path to ds-identify on redhat systems [Ryan Harper] (LP: #1833264)
tools/build-on-freebsd: update to python3 [Gonéri Le Bouder]
curtin
vmtests: drop skip_by_date decorators for bug 1813228 [Daniel Watkins]
block: Add opportunistic zkey encryption if supported [Ryan Harper]
vmtests: add support for CURTIN_VMTEST_APT_PROXY [Daniel Watkins]
vmtests: add use of CURTIN_VMTEST_ prefixed envvars to image sync [Daniel Watkins]
Below is a summary of uploads to the development and supported releases. Current status of the Debian to Ubuntu merges is tracked on the Merge-o-Matic page. For a full list of recent merges with change logs please see the Ubuntu Server report.
Proposed Uploads to the Supported Releases
Please consider testing the following by enabling proposed, checking packages for update regressions, and making sure to mark affected bugs verified as fixed.
By now you may have seen Ubuntu’s blog post (Statement on 32-bit i386 packages for Ubuntu 19.10 and 20.04 LTS) and saw that it mentions Ubuntu Studio as being one of the catalysts behind the change-of-plans. You may also be wondering why Ubuntu Studio would be concerned with this. While we did cease building 32-bit […]
Mobile operators face a range of challenges today from saturation, competition and regulation – all of which are having a negative impact on revenues. The introduction of 5G offers new customer segments and services to offset this decline. However, unlike the introduction of 4G which was dominated by consumer benefits, 5G is expected to be driven by enterprise use. According to IDC, enterprises will generate 60 percent of the world’s data by 2025.
Rather than rely on costly proprietary hardware and operating models, the use of open source technologies offers the ability to commoditise and democratise the wireless network infrastructure. Major operators such as Vodafone, Telefonica and China Mobile have already adopted such practices.
Shifting to open source technology and taking a software defined approach enables mobile operators to differentiate based on the services they offer, rather than network coverage or subscription costs.
This whitepaper will explain how mobile operators can break the proprietary stranglehold and adopt an open approach including:
The open source initiatives and technologies available today and being adopted by major operators.
How a combination of software defined radio, mobile base stations and 3rd party app development can provide a way for mobile operators to differentiate and drive down CAPEX
Use cases by Vodafone and EE on successful implementations by adopting an open source approach
To view the whitepaper, sign up using the form below:
<noscript><a class="p-link--external" href="https://ubuntu.com/engage/ubuntu-lime-telco?utm_source=blog&utm_medium=Blog&utm_campaign=FY19_IOT_UbuntuCore_Whitepaper_LimeSDR">Get the whitepaper</a>
</noscript>
The purpose of this communication is to provide a status update and highlights for any interesting subjects from the Ubuntu Server Team. If you would like to reach the server team, you can find us at the #ubuntu-server channel on Freenode. Alternatively, you can sign up and use the Ubuntu Server Team mailing list or visit the Ubuntu Server discourse hub for more discussion.
Spotlight: Weekly Ubuntu Server team updates in Discourse
The Ubuntu Server team will now be sending weekly team updates to discourse to give a clear view of the projects, feature and bug work we are working on each week. Come see what we are up to and participate in driving Ubuntu Server changes with us. Here is our June 24 status update. Come discuss any topics of interest with us.
cloud-init
doc: indicate that netplan is default in Ubuntu now [Daniel Watkins]
azure: add region and AZ properties from imds compute location metadata [Chad Smith]
sysconfig: support more bonding options [Penghui Liao]
cloud-init-generator: use libexec path to ds-identify on redhat systems [Ryan Harper] (LP: #1833264)
tools/build-on-freebsd: update to python3 [Gonéri Le Bouder]
curtin
vmtests: drop skip_by_date decorators for bug 1813228 [Daniel Watkins]
block: Add opportunistic zkey encryption if supported [Ryan Harper]
vmtests: add support for CURTIN_VMTEST_APT_PROXY [Daniel Watkins]
vmtests: add use of CURTIN_VMTEST_ prefixed envvars to image sync [Daniel Watkins]
Below is a summary of uploads to the development and supported releases. Current status of the Debian to Ubuntu merges is tracked on the Merge-o-Matic page. For a full list of recent merges with change logs please see the Ubuntu Server report.
Proposed Uploads to the Supported Releases
Please consider testing the following by enabling proposed, checking packages for update regressions, and making sure to mark affected bugs verified as fixed.
I saw a few cases of those situations happening recently
System76 / Pop! OS finds a bug (where ‘find’ often means that they confirm an existing upstream bug is impacting their OS version)
They write a patch or workaround, include it in their package but don’t upstream the change/fix (or just drop a .patch labelled as workaround in a comment rather than submitting it for proper review)
Later-on they start commenting on the upstream (Ubuntu, GNOME, …) bugs trackers, pointing out to users that the issue has been addressed in Pop! OS, advertising how they care about users and that’s why they got the problem solved in their OS
System76 / Pop! OS team, while you should be proud of the work you do for you users I think you are going the wrong way there. Working on fixes and including them early in your product is one thing, not upstreaming those fixes and using that for marketing you as better than your upstreams is a risky game. You might be overlooking that now, but divergence has a cost, as does not having good relationship with your upstreams.
We’ve updated the youtube-dl package to a newer version. This package, maintained by Debian and Canonical, is used for downloading videos from YouTube. Changes made by Google to the YouTube API had recently broken this package in the Ubuntu repositories, hence the update.
As the description mentions, they are using the Ubuntu package (which is coming from Debian). I went to check a bit more what happened and what’s the status of the fix, and oh, surprises! – they didn’t report the bug in launchpad – they didn’t send their patch/fix to launchpad – they didn’t get in touch with Ubuntu/Canonical about fixing the issue in a SRU
So instead of working with their upstream on a fix which would benefit Ubuntu and Pop! OS users they did an upload in their overlay PPA with as description ‘ * Backport to Pop!_OS because Ubuntu is too slow.’
Thanks System76 for not trying to work with us and then stab us in the back with that package description.
Ubuntu users, sorry that we didn’t get to fix that earlier since it was not brought to our attention, I did upload SRUs for Bionic and Disco now, details on https://bugs.launchpad.net/ubuntu/+source/youtube-dl/+bug/1831778
Over the past several months, we have shared with you several articles and tutorials showing how to accelerate application development so that a typically demanding, time-consuming process becomes an easier, faster and more fun one. Today, we’d like to introduce some additional tips and tricks. Namely, we want to talk about elegant ways you can streamline the final steps of a snap build.
Snap try
A rather handy thing you can do to speed up the development and testing is the snap try command. It allows you to install a snap AND make live (non-metadata) changes to the snap contents without having to go through the build process. This may sound a little confusing, so let’s discuss a practical example.
Say you built a snap, and you want to test how it works. Typically, the standard process is to install the snap (with the –dangerous flag), and then run the snap. Early in the testing process, a likely scenario is that a snap may not launch because it could be missing runtime libraries. With the usual development model, you would iterate in the following manner:
Edit the snapcraft.yaml.
Add relevant stage packages to include necessary runtime libraries.
Re-run the build process.
Remove the installed snap.
Install the new version and test again.
This is perfectly fine, but it can take some time. The alternative approach with snap try allows you to make live changes to your snap without going through the rebuild process. The way snap try works, it installs the snap, and it uses the specified directory (containing the valid snap contents) as its root. If you make non-metadata changes there, they will be automatically reflected. For instance, you can add libraries into usr/lib or lib, and see whether you can resolve runtime issues during the test phase. Once you’re satisfied the snap works well, you can then make the one final build.
Where do you start?
The easiest way is to simply unsquash a built snap, make changes to the contents contained inside the extracted squashfs-root directory, and then snap try against it, and see whether you have a successful build with all the assets correctly included. Moreover, with snap try, you can also change confinement modes, which gives you additional flexibility in testing your snap under different conditions, and see whether the application works correctly.
snap try electron-quick-start 1.0.0 mounted from /home/igor/snap-tests/electron-quick-start/dist/squashfs-root
Snapcraft pack
Side by side with snap try, you can use the snapcraft pack command. It lets you create a snap from a directory holding a valid snap (the layout of the target directory must contain a meta/snap.yaml file). Going back to our previous example, you would alter the contents of your project directory, add assets (like libraries), and then pack those into a squashfs file.
The two commands, snap try and snapcraft pack, complement each other really well. For instance, while you cannot make live changes to metadata for snap try without reinstalling the snap (directory), you can edit the snap.yaml file and pack additional snaps, allowing you to quickly test new changes.
You can also manually create your own snap and pack them for both offline and online distribution. This might be useful if your application language isn’t currently supported as a plugin in snapcraft, or if you have ready archives of binary code you want to assemble into snaps in a quick and convenient way.
Summary
Sometimes, small things can make a big difference. The ability to quickly make changes to your snaps in the testing phase, while still retaining the full separation and containment from the underlying system provides developers with the peace of mind they need to iterate quickly and release their applications. Snap try and snapcraft pack are convenient ways to blend the standard build process and runtime usage in a streamlined manner. As always, if you have any comments or suggestions, please join our forum for a discussion.
Facebook is a business selling very targeted advertising channels. This is not new, Royal Mail Advertising Mail service offers ‘precision targeting’. But Facebook does it with many more precision options, with emotive impact because it uses video and feels like it comes from your friends and the option of anonymity. This turns out to be most effective in political advertising. There are laws banning political advertising on television because politics should be about reasoned arguments not emotive simplistic soundbites but the law has yet to be changed to include this ban on video on the internet. The result has undermined the democracy of the UK during the EU referendum and elsewhere.
To do this Facebook collects data and information on you. Normally this isn’t a problem but you never know when journalists will come sniffing around for gossip in your past life, or an ex-partner will want to take something out of context to prove a point in diverse proceedings. The commonly used example of data collection going wrong was the Dutch government keeping a list of who was Jewish, with terrible consequences when the Nazis invaded. We do not have a fascist government here but you can never assume it will never happen. Facebook has been shown to care little for data protection and allowed companies such as Cambridge Analytica to steal data illegally and without oversight. Again this was used to undermine democracy using the 2016 EU referendum.
In return we get a useful way to keep in touch with friends and family and have discussions with groups and chat with people, these are useful services. So what can you do if you don’t want your history to be kept by an untrusted third party? Delete your account and you’ll miss out on important social interactions. Well there’s an easy option that nobody seems to have picked up on which is to open a new account and move your important content over but dropping your history.
Thanks to the EU legislation GDPR we have a Right to Data Portability. This is similar but separate from the Right to Access. And it means it’s easy enough to extract your data out of Facebook. I downloaded mine and it’s a whopping 4GB of text and photos and Video. I then set up a new account and started triaging anything I wanted to keep. What’s in my history?
Your Posts and Other People’s Posts to Your Timeline
These are all ephemeral. You post them, get some reaction, but they’re not very interesting a week or more later. Especially all the automated ones Spotify sent saying what music I was playing.
Photos and videos
Here’s a big chunk. Over 1500, some 2GB of pics, mostly of me looking awesome paddling. I copied any I want to keep over to easy photo dump Google Photos. There was about 250 I wanted to keep.
Comments
I’ve really no desire to keep these.
Likes and reactions
Similarly ephemeral.
Friends
This can be copied over easily to a new account, you just friend your old account and then it’ll suggest all your old friends. A Facebook friend is not the same as a real life friend so it’s sensible to triage out anyone you don’t have contact with and don’t find interesting to get updates from.
You can’t see people who have unfriended you, probably for the best.
Stories
Facebook’s other way to post pics to try to be cool with the Snapchat generation. Their very nature is that they don’t stay around long so nothing important here.
Following and followers
This does include some people who have ignored a friend request but still have their feed public so that request gets turned into a follow. Nobody who I deperately crave to be my friend is on the list fortunately so they can be ignored.
Messages
Despite removing the Facebook branding from their messaging service a few years ago it’s still very much part of Facebook. Another nearly 2GB of text and pics in here. This is the kind of history that is well worth removing, who knows when those chats will come back to haunt you. Some more pics here worth saving but not many since any I value for more than a passing comment are posted on my feed. There’s a handful of longer term group chats I can just add my new account back into.
Groups
One group I run and a few I use frequently, I can just rejoin them and set myself as admin on the one I run.
Events
Past events are obviously not important. I had 1 future event I can easily rejoin.
Profile information
It’s worth having a triage and review of this to keep it current and not let Facebook know more than you want it to.
Pages
Some pages I’m admin or moderator of than I can rejoin, where moderator you need to track down an admin person to add you back in.
Marketplace, Payment history, Saved items and collections, Your places
I’ve never found a use for these features.
Apps and websites
It’s handy to use Facebook as a single sign on for websites sometimes but it’s worth reviewing and triaging these to stop them taking excess data without you knowing. The main one I used was Spotify but it turns out that has long since been turned into a non-Facebook account so no bother wiping all these.
Other activity
Anyone remember pokes?
What Facebook Decides about me
Facebook gives you labels to give to advertisers. Seems I’m interested in Swahili language, Sweetwater in Texas, Secret Intelligence Service and other curiosities.
Search history
I can’t think of any good reason why I’d want Facebook to know about 8 years of searches.
Location history
Holy guacamole, they keep my location each and every day since I got a smartphone. That’s going to be wiped.
Calls and messages
Fortunately they haven’t been taking these from my phone history but I’m sure it’s only one setting away before they do.
Friend Peer Group
They say I have ‘Established Adult Life’. I think this means I’m done.
Your address books
They did however keep all my contacts from GMail and my phone whenever I first logged on from a web browser and phone. They can be gone.
So most of this can be dropped and recreated quite easily. It’s a fun evening going through your old photos. My 4GB of data is kept in a cloud drive which can be accessed through details in my will so if I die and my autobiographer wants to dig the gossip on me they can.
I also removed the app from my phone. The messenger app is useful but the Facebook one seems a distraction, if I want to browse and post Facebook stuff I can use the web browser. And on a desktop computer I can use https://www.messenger.com/ rater than the distraction of the Facebook website.
The Lubuntu Team is happy to announce that we now have ways that you can directly donate to the project and purchase apparel. You can find quick links to all of the sites described in this post on our Donate page. Why does Lubuntu need donations? Lubuntu is a community-developed project that relies on support […]
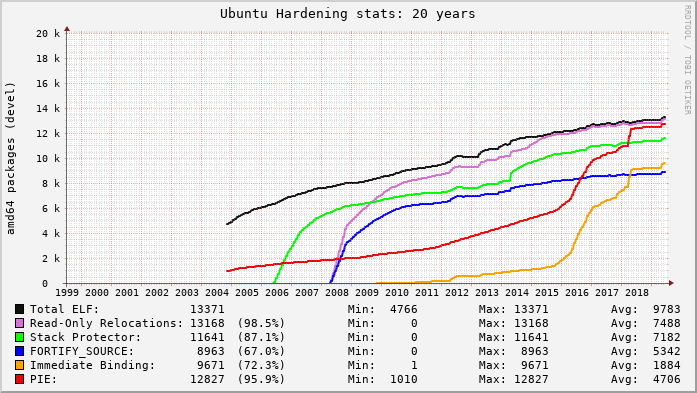
Forever ago I set up tooling to generate graphs representing the adoption of various hardening features in Ubuntu packaging. These were very interesting in 2006 when stack protector was making its way into the package archive. Similarly in 2008 and 2009 as FORTIFY_SOURCE and read-only relocations made their way through the archive. It took a while to really catch hold, but finally PIE-by-default started to take off in 2016 through 2018:
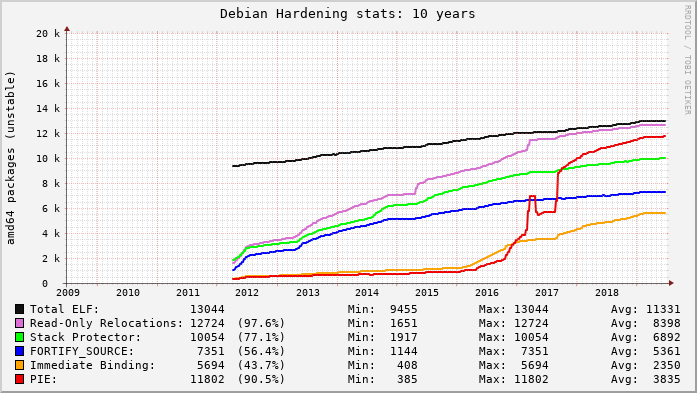
Around 2012 when Debian started in earnest to enable hardening features for their archive, I realized this was going to be a long road. I added the above “20 year view” for Ubuntu and then started similarly graphing hardening features in Debian packages too (the blip on PIE here was a tooling glitch, IIRC):
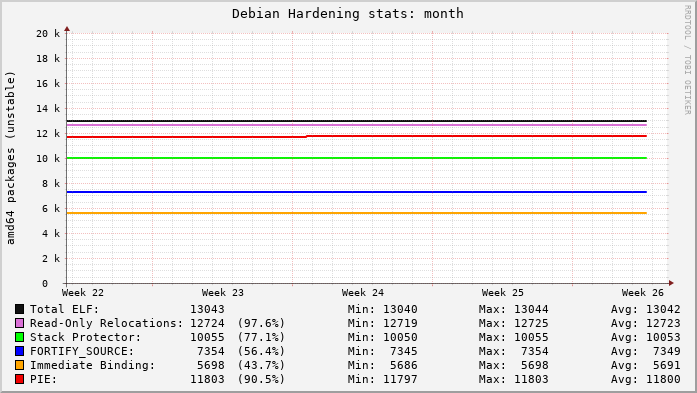
Today I realized that my Ubuntu tooling broke back in January and no one noticed, including me. And really, why should anyone notice? The “near term” (weekly, monthly) graphs have been basically flat for years:
In the long-term view the measurements have a distinctly asymptotic appearance and the graphs are maybe only good for their historical curves now. But then I wonder, what’s next? What new compiler feature adoption could be measured? I think there are still a few good candidates…
Or how about getting serious and using forward-edge Control Flow Integrity? (Clang has -fsanitize=cfi for general purpose function prototype based enforcement, and GCC has the more limited -fvtable-verify for C++ objects.)
Where is backward-edge CFI? (Is everyone waiting for CET?)
Does anyone see something meaningful that needs adoption tracking?
This month:
* Command & Conquer
* How-To : Python, Freeplane, and Darktable pt4
* Graphics : Inkscape
* My Story: Installing Ubuntu
* Linux Loopback
* Everyday Ubuntu: Getting Help
* Book Review: Math Adventures With Python
* Review: Lubuntu 19.04
* Linux Certified
* Ubuntu Games: Auto-Chess Pt1
plus: News, The Daily Waddle, Q&A, Crossword and more.
Eventually I will get the script
written for the short film I intend to enter into the Dam Short Film Festival near Hoover
Dam in Boulder City, Nevada. A combination of LaTeX, git,
Launchpad, imagination, and ingenuity might actually help me get
the script written. Making the film is the challenge yet to come,
though.
I am apparently still reachable via Telegram if anybody wants to call.
I'm still boggled by the varieties of non-free Javascript
utilized in this Bodyweight
Planner put forward by an entity in the US Department of Health
and Human Services. It isn't a bad tool, mind you. Having a
disconnected tool would be nicer, though. Major storms rolled
through on Saturday morning causing power disruptions and some
felled trees damaging houses. Life in the deciduous forest is
rough.
Work has been a bit disturbing lately. When you're left
contemplating the questions I have been stuck with generally major
life changes end up happening. I don't like where things have wound
up lately. I threw three job inquiries in the mail Saturday and
since attending OggCamp is looking outside my grasp I won't be
floating CV/resume documents there, alas. No, things are not okay
right now.
As a quick note, I should reference that the package from CTAN
that I am using to prepare the script for the work-in-progress
short film is the stage
package. Yes, I understand it is intended for stage plays. It suits
our purposes, though. You can track development on Launchpad and
clone the git repository from https://code.launchpad.net/~skellat/+git/TheFilm
since I want to promote Launchpad as an off-beat alternative to
GitHub.
For my money, the height of the smartphone age was 2009-2011. That brought us the Nokia n900 and Nokia n9. Both brilliant for their own reasons. There were devices before that which I’d be happy to have back. But nothing since then. Sure, the Ubuntu Edge or Neo900 would have been great. But they never came to be.
So my current phone is chosen to match my lifestyle: A rugged Sonim XP5 . It runs Android. Without the full store, but you can sideload apps. It has no touchscreen, and only a numeric keypad. But it’s still pretty decent for one-handed operation. It does what I want out of a phone:
Calls
SMS
Email (with hacked K-9 Mail version)
Alarms and timer.
Flashlight, on/off with one button, no going through gui.
Browser. Just useful enough to look up a business, see its hours, and call.
I wrote this some time ago but hadn’t posted it. Very lately I’ve actually been playing with sailfish. I really like the interface, but it’s not very reliable. I’m considering trying out ubuntu touch. I don’t really want to buy another phone (nexus 5), and ubuntu touch is known to not be working fully on my secondary phone, but I should be able to help with that, especially as there is mention of not attaching to LXC containers *duck*. Just have to decide I’m willing to remove sailfish.
21 years in, the landscape around open source evolved a lot. Today, "open
source" is not enough. In my opinion it is necessary, but it is not
sufficient. In this 3-part series I'll detail why, starting with Part 1
-- why open source is necessary today.
What open source is
Free software started in the 80’s by defining a number of freedoms. The
author of free software has to grant users (and future contributors to
the software) those freedoms. To summarize, those freedoms made you free
to study, improve the software, and distribute your improvements to the
public, so that ultimately everyone benefits. That was done in reaction
to the apparition of "proprietary" software in a world that previously
considered software a public good.
When open source was defined in 1998, it focused on a more specific angle:
the rights users of the software get with the software, like access to the
source code, or lack of constraints on usage. This straight focus on user
rights (and less confusing naming) made it much more understandable to
businesses and was key to the success of open source in our industry today.
Despite being more business-friendly, open source was never a "business
model". Open source, like free software before it, is just a set of
freedoms and rights attached to software. Those are conveyed through software
licenses and using copyright law as their enforcement mechanism. Publishing
software under a F/OSS license may be a component of a business model, but
if is the only one, then you have a problem.
Freedoms
The freedoms and rights attached to free and open source software bring
a number of key benefits for users.
The first, and most-often cited of those benefits is cost. Access
to the source code is basically free as in beer. Thanks to the English
language, this created interesting confusion in the mass-market as to
what the "free" in "free software" actually meant. You can totally sell
"free software" -- this is generally done by adding freedoms or bundling
services beyond what F/OSS itself mandates (and not by removing freedoms,
as some recently would like you to think).
If the cost benefit has proven more significant as open source evolved,
it's not because users are less and less willing to pay for software or
computing. It's due to the more and more ubiquitous nature of computing. As
software eats the world,
the traditional software pay-per-seat models are getting less and less
adapted to how users work, and they create extra friction in a world
where everyone competes on speed.
As an engineer, I think that today, cost is a scapegoat benefit. What
matters more to users is actually availability. With open source
software, there is no barrier to trying out the software with all of its
functionality. You don't have to ask anyone for permission (or enter any
contractual relationship) to evaluate the software for future use, to
experiment with it, or just to have fun with it. And once you are ready
to jump in, there is no friction in transitioning from experimentation
to production.
As an executive, I consider sustainability to be an even more
significant benefit. When an organization makes the choice of deploying
software, it does not want to left without maintenance, just because
the vendor decides to drop support for the software you run, or just
because the vendor goes bankrupt. The source code being available for
anyone to modify means you are not relying on a single vendor for
long-term maintenance.
Having a multi-vendor space is also a great way to avoid lock-in. When
your business grows a dependency on software, the cost of switching to
another solution can get very high. You find yourself on the vulnerable
side of maintenance deals. Being able to rely on a market of vendors
providing maintenance and services is a much more sustainable way of
consuming software.
Another key benefit of open source adoption in a corporate setting is
that open source makes it easier to identify and attract talent.
Enterprises can easily identify potential recruits based on the open
record of their contributions to the technology they are interested in.
Conversely, candidates can easily identify with the open source
technologies an organization is using. They can join a company with
certainty that they will be able to capitalize on the software experience
they will grow there.
A critical benefit on the technical side is transparency. Access to
the source code means that users are able to look under the hood and
understand by themselves how the software works, or why it behaves
the way it does. Transparency also allows you to efficiently audit
the software for security vulnerabilities. Beyond that, the ability to
take and modify the source code means you have the possibility of
self-service: finding and fixing issues by yourself, without even
depending on a vendor. In both cases that increases your speed in
reacting to unexpected behavior or failures.
Last but not least: with open source you have the possibility to engage
in the community developing the software, and to influence its direction
by contributing directly to it. This is not about "giving back" (although
that is nice). Organizations that engage in the open source communities
are more efficient, anticipate changes, or can voice concerns about
decisions that would adversely affect them. They can make sure the
software adapts to future needs by growing the features they will
need tomorrow.
Larger benefits for ecosystems
Beyond those user benefits (directly derived from the freedoms and rights
attached to F/OSS), open source software also has positive effects to
wider ecosystems.
Monopolies are bad for users. Monocultures are vulnerable environments.
Open source software allows challengers to group efforts and collaborate
to build an alternative to the monopoly player. It does not need to beat
or eliminate the proprietary solution -- being successful is enough to
create a balance and result in a healthier ecosystem.
Looking at the big picture, we live on a planet with limited natural goods,
where reducing waste and optimizing productivity is becoming truly
critical. As software gets pervasive and more and more people produce it,
the open source production model reduces duplication of effort and the waste
of energy of having the same solutions developed in multiple parallel
proprietary silos.
Finally, I personally think a big part of today's social issues is the
result of artificially separating our society between producers and
consumers. Too many people are losing the skills necessary to build
things, and are just given subscriptions, black boxes and content to
absorb in a well-oiled consumption machine. Free and open source software
blurs the line between producers and consumers by removing barriers and
making every consumer a potential producer. It is part of the solution
rather than being part of the problem.
All those benefits explain why open source software is so successful today.
Those unique benefits ultimately make a superior product, one that is a smart
choice for users. It is also a balancing force that drives good hygiene to
wider ecosystems, which is why I would go so far as saying it is necessary
in today's world. Next week in part 2, we'll see why today, while being
necessary, open source is no longer sufficient.
Private cloud, public cloud, hybrid cloud, multi-cloud… the variety of locations, platforms and physical substrate you can start a cloud instance on is vast. Yet once you have selected an operating system which best supports your application stack, you should be able to use that operating system as an abstraction layer between different clouds.
However, in order to function together an operating system and its cloud must share some critical configuration data which tells the operating system how to ‘behave’ in the particular environment. Separating out this configuration data from the operating system and the underlying cloud is the key to effortlessly launching instances across multi-cloud.
Cloud-init provides a mechanism for separating out configuration data from both the operating system and the execution environment so that you maintain the ability to change either at any time. It serves as a useful abstraction which ensures that the investments you make in your application stack on a specific operating system can be leveraged across multiple clouds.
This whitepaper will explain:
The background and history behind the cloud-init open source project
How cloud-init is invoked and how it configures an instance
How to get started with cloud-init
To view the whitepaper sign up using the form below:
<noscript><a class="p-link--external" href="https://ubuntu.com/engage/cloud-init-whitepaper?utm_source=Blog&utm_medium=Blog&utm_campaign=CY19_DC_Server_Whitepaper_CloudInit">Get the whitepaper</a>
</noscript>









 Screenshot of my MediaDrop instance.
Screenshot of my MediaDrop instance. LBRY App Screenshot
LBRY App Screenshot